Antigravity-kit 操作手册 By Claude
最近在使用 Google Antigravity 进行 Vibe Coding,看到了一个有意思的工具:antigravity-kit ,于是分别利用 Claude 和 Gemini 制作了操作手册,这一份是 Claude 的
Antigravity Kit 最佳实践操作手册
照着做就 OK — 全栈全链路 Vibecoding 场景专版
版本: 基于 antigravity-kit v2.0.0
适用编辑器: Google Antigravity / Cursor / Windsurf
核心前提: 本手册的所有场景均假设项目为全栈全链路开发(前端 + 后端 + 数据库),因此 /orchestrate 是执行阶段的默认命令,而非特殊选项。
目录
- 三件事先搞清楚
- 全局准备:安装与配置
- 场景一:新建项目
- 场景二:已有项目完善
- 场景三:重构项目
- 全栈场景 Prompt 写法指南
- Agents 速查手册
- Workflows 速查手册
- 常见问题 & 避坑指南
三件事先搞清楚
1. 三个核心概念
| 概念 | 是什么 | 怎么触发 |
|---|---|---|
| Agent | 专家 AI 角色(前端/后端/安全等 20 种) | 自动路由,或手动 Use the xxx-agent to... |
| Skill | 领域知识模块(React/测试/部署等 37 个) | 按上下文自动加载,无需手动操作 |
| Workflow | Slash 命令工作流(11 个标准流程) | 直接输入 /命令 描述 |
2. 全栈场景的命令默认逻辑
| 阶段 | 默认命令 | 理由 |
|---|---|---|
| 需求不清晰 | /brainstorm |
先想清楚再动手 |
| 需求清晰、准备开工 | /plan |
生成任务分解 |
| 执行任何功能 | /orchestrate |
全栈项目每个功能必然跨前端+后端+数据库 |
| 仅改 UI 样式/文案 | /ui-ux-pro-max 或直接描述 |
唯一不需要多 Agent 的情况 |
| 出现 Bug | /debug |
系统性排查 |
| 纯代码质量改善 | /enhance |
不涉及功能变更的重构 |
| 上线前 | /test → /deploy |
固定顺序 |
3. /orchestrate 的本质
/orchestrate 不是”高级的 /create“,它是一个项目经理:把你的需求拆解成子任务,然后依次调度 frontend-specialist、backend-specialist、database-architect、security-auditor、test-engineer 等专家顺序执行,最后合并验证。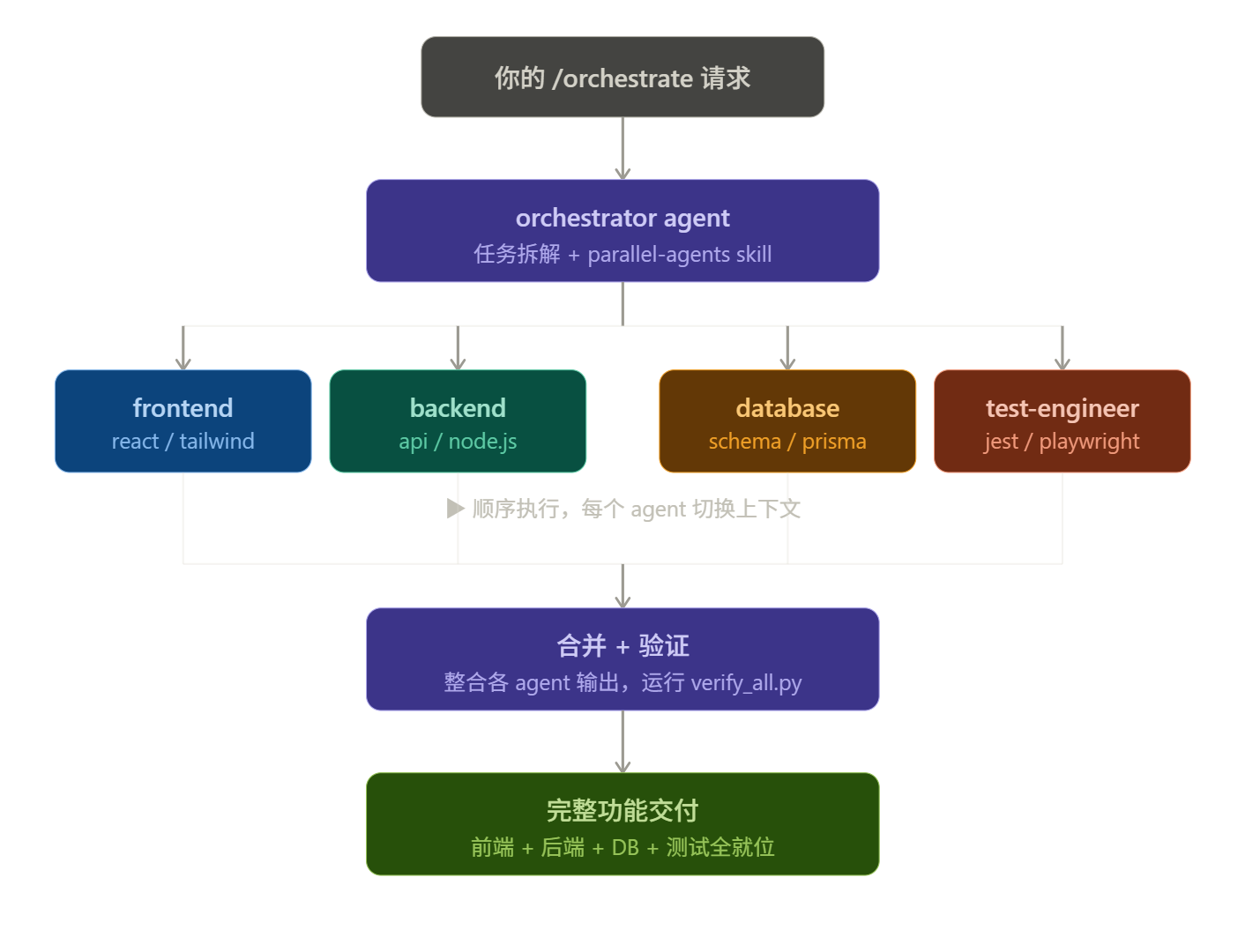
全栈项目里,每个功能都会同时触碰前端+后端+数据库,因此 /orchestrate 是你在执行阶段应该形成肌肉记忆的命令。
全局准备:安装与配置
第一步:安装 CLI
1 | # 一次性使用(推荐,无需全局污染) |
安装完成后,项目根目录会出现 .agent/ 文件夹:
1 | .agent/ |
第二步:配置 Git(关键,不可跳过)
⚠️ 不要把 .agent/ 加入 .gitignore,否则 Antigravity 无法索引 workflows,所有 Slash 命令都不会出现在建议下拉框。
正确做法:加入本地排除文件(仅对你本机生效,不提交到远端):
1 | echo ".agent/" >> .git/info/exclude |
第三步:验证安装
1 | ag-kit status |
更新(日后需要时)
1 | ag-kit update |
场景一:新建项目
从零开始,有想法但尚未动工。
标准流程
1 | /brainstorm → /plan → /orchestrate → /test → /preview → /deploy |
Step 1 — 想清楚再动手:/brainstorm
1 | /brainstorm 我想做一个 SaaS 任务管理工具,多用户,有团队协作,支持截止日期和提醒 |
Kit 用苏格拉底式提问引导你明确:目标用户、核心功能边界、技术约束、MVP 范围。
✅ 产出: 结构化需求文档。把这份输出保留,下一步直接用。
Step 1.5 — 确立数字契约:生成 docs/PRD.md
/brainstorm 结束、需求基本对齐之后,在进入任何执行步骤之前,先让 AI 把共识固化成一个项目内的真实文件:
1 | Use the product-manager to generate docs/PRD.md based on the above brainstorm, |
生成后你来审核:检查数据模型有没有漏字段、MVP 边界有没有写错、有没有你不想要的功能被 AI 自作主张加进去。确认后再往下走。
如果审核发现问题,直接告诉 AI 修正:
1 | PRD 里数据模型漏了 avatar_url 字段; |
✅ 为什么这一步不能跳过:
/orchestrate 会同时调度数据库、后端、前端三个 Agent。如果没有一份统一的 PRD,前端生成的字段可能跟数据库对不上,后端的接口返回格式可能跟前端预期不符。docs/PRD.md 是多 Agent 协作的公共上下文——它是宪法,不是文档。
此外,它还解决了 Vibecoding 最大的实际痛点:跨会话的项目记忆。几天后你重新打开项目、AI 上下文已清空时,一句话就能找回全部状态:
1 | /status 请阅读 docs/PRD.md 并告诉我当前开发进度和待完成的功能 |
Step 2 — 分解任务:/plan
1 | /plan 请严格遵循 docs/PRD.md 中的要求和 MVP 边界,生成全栈开发任务拆解清单, |
✅ 产出: 带优先级的任务列表 + 技术选型建议(前端框架、后端语言、数据库方案)。
Step 3 — 生成完整项目骨架:/orchestrate
把 Step 2 确认的技术选型填进去,并显式引用 PRD:
1 | /orchestrate 请所有参与的 Agent 在写代码前先读取 docs/PRD.md 对齐业务逻辑和数据模型, |
/orchestrate 内部会依次调用:
@backend-specialist搭建 API 层@database-architect设计 Schema 和迁移@frontend-specialist搭建页面结构@security-auditor检查认证安全性@test-engineer生成基础测试
Step 4 — UI 精调(可选):/ui-ux-pro-max
1 | /ui-ux-pro-max 为任务管理应用设计 Dashboard 主页面,风格:现代简洁,暗色主题,数据密度适中 |
内置 50 种风格 + 21 种调色板,会给出多方案供选。
Step 5 — 补全测试:/test
1 | /test 为整个项目生成测试套件:单元测试(Jest)+ E2E 测试(Playwright),覆盖核心用户流程 |
Step 6 — 本地跑起来:/preview
1 | /preview |
Step 7 — 部署:/deploy
1 | /deploy 部署到 Vercel,连接 Supabase PostgreSQL,配置环境变量 |
新项目标准 Prompt 模板(复制即用)
1 | # Step 1 |
场景二:已有项目完善
项目已在运行,需要加功能、修 Bug、做优化。
加新功能(全栈功能,每次都用 /orchestrate)
全栈项目里,几乎所有功能都会同时动到三层,直接用 /orchestrate 就对了:
1 | /orchestrate 添加消息通知系统: |
1 | /orchestrate 接入 Stripe 订阅支付: |
1 | /orchestrate 添加团队协作功能: |
唯一不需要 /orchestrate 的情况: 纯 UI/样式调整,不涉及数据或逻辑变更。
1 | # 这种直接描述就行 |
1 | # 或用 /ui-ux-pro-max |
修 Bug:/debug
1 | /debug 用户登录后跳转 /dashboard 出现 500 错误,日志如下: |
Kit 加载 systematic-debugging Skill,执行:根因分析 → 定位代码 → 给出修复 → 建议验证步骤。
给的信息越完整效果越好,理想信息包括:错误日志、复现步骤、相关代码片段、最近一次改动了什么。
性能问题
1 | 产品列表页 LCP 超过 4 秒,需要优化,目标 LCP < 2.5s |
或指定 Agent:
1 | Use the performance-optimizer to analyze and fix the slow loading of the product listing page |
安全审查(每次加涉及权限的功能后必做)
1 | Use the security-auditor to review the new subscription and permission system for security vulnerabilities |
检查项目整体健康状态
1 | /status 请阅读 docs/PRD.md 并告诉我当前开发进度、已完成功能和待完成功能 |
这个用法在跨会话回到项目时特别有用——AI 上下文已清空,但 PRD 文件还在,一句话就能恢复全部项目记忆。
已有项目 Prompt 快速参考表
| 需求类型 | 命令 | 备注 |
|---|---|---|
| 加任何全栈功能 | /orchestrate [功能描述,说清三层] |
默认选项 |
| 纯 UI 样式调整 | 直接描述 或 /ui-ux-pro-max |
唯一不用 /orchestrate 的情况 |
| Bug 修复 | /debug [描述 + 日志] |
附上完整错误信息 |
| 代码质量改善 | /enhance [模块描述] |
不改功能,只改代码质量 |
| 加测试覆盖 | /test [要测试的功能/模块] |
功能完成后必做 |
| 性能优化 | 描述问题 或 Use the performance-optimizer |
|
| 安全审查 | Use the security-auditor to review... |
涉及权限/认证的功能完成后必做 |
| 写 API 文档 | Use the documentation-writer to... |
|
| 查项目现状 | /status |
场景三:重构项目
老项目技术债严重,或需要系统性架构改造。
重构铁律: 分析 → 计划 → 分阶段执行 → 持续验证。每个阶段结束后系统必须仍可运行,不允许出现”重构到一半无法启动”的状态。
Step 1 — 读懂现有代码库
先让专门的 Agent 探索,不要自己猜:
1 | Use the code-archaeologist to analyze the entire codebase and output: |
或者侧重理解结构:
1 | Use the explorer-agent to map the codebase structure and identify all data flows between frontend, backend, and database |
Step 2 — 讨论重构策略
把 Step 1 的分析结果直接喂进去:
1 | /brainstorm 当前代码库分析结果如下:[粘贴 Step 1 输出] |
Step 3 — 制定重构计划
1 | /plan 基于以上讨论,制定详细的全栈重构计划: |
Step 4 — 分阶段执行
架构级重构(涉及多层):/orchestrate
1 | /orchestrate 执行重构计划第一阶段:将 Express 路由层重构为分层架构(Controller → Service → Repository): |
纯代码质量改善(不改架构):/enhance
1 | /enhance 重构 src/services/ 目录:消除重复代码,提取公共工具函数,补充 TypeScript 类型,遵循 clean-code 原则 |
数据库结构改造:
1 | /orchestrate 重构数据库层以支持多租户: |
Step 5 — 每阶段结束后补测试
1 | /test 为刚完成重构的 [模块名] 生成完整测试,覆盖所有原有功能点,确保无回归 |
Step 6 — 验证
1 | # 开发阶段快速验证 |
Step 7 — 性能和安全复查
1 | Use the performance-optimizer to verify no performance regression after the refactoring |
重构 Prompt 快速参考表
| 阶段 | 命令 |
|---|---|
| 读懂老代码 | Use the code-archaeologist to analyze... |
| 摸清代码结构 | Use the explorer-agent to map... |
| 讨论策略 | /brainstorm [粘贴分析结果] |
| 制定计划 | /plan 制定全栈重构计划,含每阶段范围和验收标准 |
| 架构重构(多层联动) | /orchestrate [本阶段范围,三层分别说清楚] |
| 纯代码质量改善 | /enhance [模块描述] |
| 阶段验收测试 | /test 覆盖 [模块名] 所有原有功能点 |
| 完整验证 | python .agent/scripts/verify_all.py . |
| 上线前复查 | Use the security-auditor + Use the performance-optimizer |
全栈场景 Prompt 写法指南
核心原则:把三层说清楚
/orchestrate 的效果取决于你的描述质量。描述全栈功能时,养成同时说清前端/后端/数据库各自要做什么的习惯:
❌ 模糊写法:
1 | /orchestrate 添加评论功能 |
✅ 清晰写法:
1 | /orchestrate 添加文章评论功能: |
不知道技术细节怎么写?先跑 /plan
如果你对某层不熟悉(比如不清楚数据库表应该怎么设计),先用 /plan 让系统帮你想:
1 | /plan 为评论功能制定详细实现方案,包含前端/后端/数据库的完整设计 |
确认 /plan 的输出后,再把它的结论作为 /orchestrate 的输入。
安全和测试不要忘记显式要求
Kit 会自动做基本检查,但在以下情况下最好显式要求:
1 | # 涉及权限的功能,在 /orchestrate 末尾加一行 |
Agents 速查手册
绝大多数时候不需要手动指定 Agent,系统自动路由。以下情况手动指定效果更好:需要某个特定专家视角(如专门要安全审计视角)、系统路由不准(出现在描述模糊的请求上)。
手动指定语法:
1 | Use the [agent-name] to [描述任务] |
全部 20 个 Agent
| Agent | 最适合的场景 |
|---|---|
orchestrator |
复杂多步全栈任务的调度协同 |
project-planner |
需求分析、任务拆解、项目规划 |
frontend-specialist |
React / Next.js / Vue UI 开发 |
backend-specialist |
API 设计、业务逻辑、Node.js / Python 后端 |
database-architect |
Schema 设计、SQL 优化、迁移方案 |
mobile-developer |
iOS / Android / React Native / Flutter |
game-developer |
游戏逻辑、物理引擎、游戏机制 |
devops-engineer |
CI/CD、Docker、部署流水线 |
security-auditor |
安全合规审查、OWASP 检查 |
penetration-tester |
渗透测试、漏洞挖掘 |
test-engineer |
测试策略、Jest / Vitest / Playwright |
debugger |
根因分析、系统性 Debug |
performance-optimizer |
速度优化、Web Vitals 提升 |
seo-specialist |
SEO、Core Web Vitals、E-E-A-T |
documentation-writer |
API 文档、用户手册、README |
product-manager |
需求文档、用户故事、PRD |
product-owner |
产品策略、Backlog 管理、MVP 定义 |
qa-automation-engineer |
E2E 测试、CI 测试流水线 |
code-archaeologist |
遗留代码分析、技术债挖掘 |
explorer-agent |
代码库结构探索和理解 |
Workflows 速查手册
全部 11 个 Workflow
| 命令 | 作用 | 全栈场景下的典型用法 |
|---|---|---|
/brainstorm |
苏格拉底式需求探索 | 需求模糊时的第一步 |
/plan |
任务拆解和技术方案 | 执行前的设计环节 |
/orchestrate |
多 Agent 全栈执行 | 执行任何全栈功能的默认命令 |
/enhance |
改善现有代码质量 | 纯技术债清理,不改功能 |
/ui-ux-pro-max |
高质量 UI 设计(50 种风格) | 纯视觉/交互调整 |
/debug |
系统性 Bug 排查 | 出现问题时 |
/test |
生成测试套件 | 功能完成后必做 |
/preview |
本地预览 | 上线前确认 |
/status |
项目健康状态检查 | 阶段性回顾 |
/deploy |
部署到生产环境 | 上线 |
/create |
创建单一模块/组件 | 仅纯前端组件或纯后端脚本等单层内容 |
关于 /create: 在全栈项目里,/create 的使用场景非常有限——仅当你需要生成一个确实不涉及其他层的孤立内容时(如一个纯展示的 UI 组件、一个独立的数据导出脚本)。只要触碰两层及以上,就用 /orchestrate。
常见问题 & 避坑指南
❌ Slash 命令不出现在建议下拉框
根因: .agent/ 被加入了 .gitignore,Antigravity IDE 无法索引。
1 | # 从 .gitignore 中移除 .agent/ 这一行 |
❌ /orchestrate 生成的代码前后端接口对不上
根因: Prompt 里没有说清楚接口契约。
解决: 在 Prompt 里明确说明期望的接口格式,或先跑 /plan 让系统设计接口,确认后再执行。
1 | /orchestrate 实现评论功能,API 格式统一为 tRPC procedures: |
❌ 重构到一半项目跑不起来
根因: 重构步子太大,多个模块同时改动造成临时不一致。
解决: 把每次 /orchestrate 的范围缩小,确保每个请求完成后系统仍可运行:
1 | # ❌ 一次重构太多 |
❌ 想在 CI/CD 中自动验证
1 | - name: Validate with ag-kit |
❌ 想加自定义 Workflow
在 .agent/workflows/ 下新建 Markdown 文件:
1 | --- |
保存为 .agent/workflows/deploy-staging.md,之后用 /deploy-staging 触发。
心法三条
先想清楚,再动手,先立契约。 用 /brainstorm 对齐想法,用 docs/PRD.md 把共识固化成文件,用 /plan 分解任务,然后再执行。PRD 不是文档,是多 Agent 的宪法,也是你跨会话的项目记忆。
描述结果,不是步骤。 告诉 Kit “我要一个带分页的评论系统,含嵌套回复”,而不是”先建表,再写 API,再做组件”——让 /orchestrate 去编排顺序,你只需要描述终态。
小步走,每步可验证。 不要一次 /orchestrate 整个大功能,按业务边界拆分成小块逐一交付。每块完成后跑测试确认,出问题定位容易,回滚也方便。